
Diffusion is compression
An attempt at a non-toxic image model explainer

So much AI confusion stems from toxic explainers designed to mislead, and bad explainers that fail to provide adequate context and grounding.
When we start from "products are like people", we approach moral and legal issues backwards. Misapplying human terms like "learning" and "inspiration" to machine process takes shallow metaphor literally, inviting all kinds of misconceptions; we miss out on fundamental distinctions in how works are being used.
The aim of this toxic conceptual apparatus as pushed by tech companies is to wriggle out of paying for essential business inputs, and present outputs as completely untethered from inputs.
Yes, models also enable transformative uses for interpreting and editing images – which is cool! Extending canvases, turning objects, tweaking facial expressions, etc.
But they are primarily used for content storage and retrieval of complete substitutes that compete in the market of the originals, drastically undermining their value.
Hence all the fuss.
Reference vs inspiration vs assets
Let us first look at the three main ways in which images are used in manual visual creation.
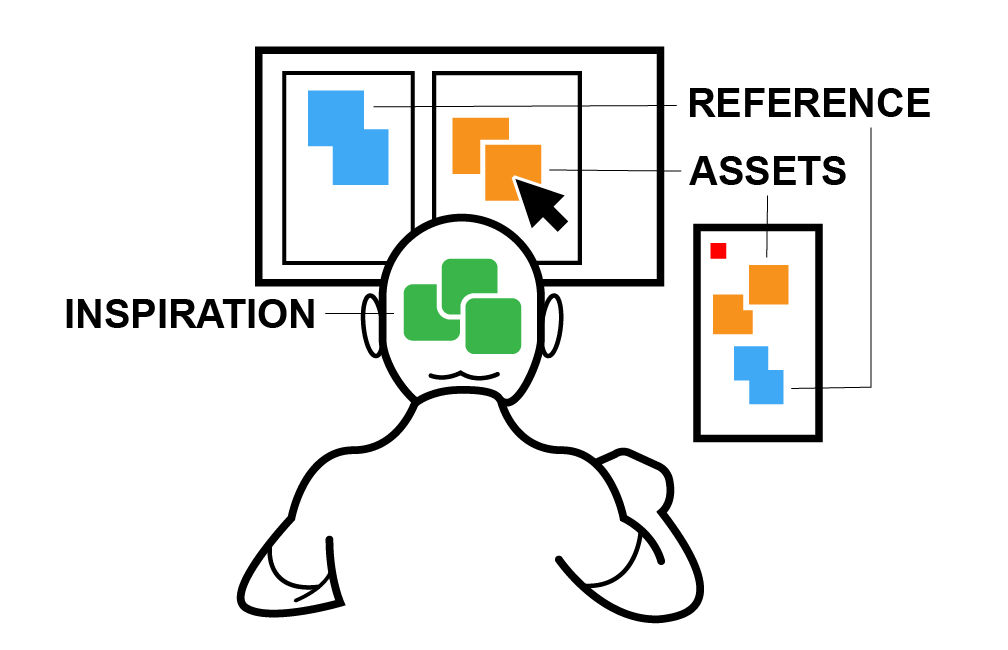
Learning and inspiration is subjective
Pattern memorization is some small aspect of it, but so are imprinting ways of seeing and doing, through imitation and practice. And inspiration carries over between all kinds of sensory impressions, dreams and memories. A mood or a vibe from a song can influence the look of a visual work, etc.
Reference is what you see
At the extreme end of using reference is tracing, where result is primary, learning secondary, and one might use a drawing as basis for a drawing. At the other extreme are art studies, where you observe or practice recreating various aspects of the reference, be it anatomy, light, volume, texture, style, artistic technique etc -- to do a dry run before tackling a challenging subject. The reference can be an object, a model, a photo or anything else you can look at.
Assets are what you use
Collage and photobashing are two examples of direct uses, where bits and pieces of pictures are assembled to form a new picture. Other examples would be a painting visible on screen in a movie, a sculpture in a photograph, a car in a videogame, a song in a video, a font in a book, a soundbite in a song, etc. Point being, these artefacts move between media and make up parts of other works, but they never enter or leave the mind of a person.
Generative AI has nothing at all to do with the first two.
There is no subjective process.
And there is no referencing.
The source materials are being used as an asset, by an enterprise, through an automated process.
Let us next look at how, properly positioning models in their technical lineage.
A brief history of compression formats
Image models are computer files like any other. Lossy storage resource files for media content. As such, they fit in a progression of efficiency innovation.
Let us first look at an uncompressed, lossless image file format:
Bitmap files store pixels independently 1:1. Each color channel (Red, Green, Blue) of each pixel is intact. Computationally cheap to render to screen from file, pixel by pixel, but inefficient in terms of storage.
GIF improves efficiency by reducing the palette from all possible colors at every pixel, to only a numbered list of the colors actually used. It then applies 1D compression: stretches of similarly coloured pixels are reduced to a colour code and a run length. You pack and unpack by counting runs of pixels.
JPEG improves efficiency by applying lossy 2D compression: reducing sets of similar color to larger blocks of average color. As with mp3s, some serious smarts go into throwing away only information that is hard for us to perceive in the first place.
Zipping those files up in an archive is more efficient yet, as that allows files with similar content to share space. You pack by identifying chunks of identical information across files and disassemble them neatly, in such a way that they can later be reassembled perfectly from the file name, without loss of information.
Each of these steps uses more computations, to save more space.
The same goes for diffusion.
Compressing image data into a diffusion model presses further by combining the zip strategy of sharing chunks with the jpg strategy of lossy compression, at several scales. You pack by identifying patterns first at the level of the entire picture, then in progressively smaller chunks. Rather than keep a table of all input files for 1:1 reassembly as with the zip file, you map only probabilities for a certain detail shape fitting a certain larger shape, and the text tags associated with the picture, at unpacking time.
Intelligence, memorization, generation
This is by no means an exhaustive explainer, but hopefully helps rid some confusing process detail to clarify what honest technologists have said all along: "intelligence is compression." That one was never about brevity as a sign of wit, but about cleverly constructed algorithms conserving storage space by running more and better math.
The above hopefully also explains memorization as a byproduct of the compression method; more copies in = higher likelihood of a particular combination of features reappearing at unpacking time.
Text-to-image is often presented as a transformation of text to image – “turn your ideas into images” – as if our choices make up the image itself.
What this aims to show more clearly is that all those choices do, is select which parts to pick.
By generative we neither mean creation from text nor creation from nothing – but a recombination of parts extracted from the underlying works and stored in the model. In this trivial example above, we see that from only four choices – all of which can be just as well be left to chance – we get a full image.
And those choices are rarely this clearly defined or predictable; there is a good deal of added randomness and pre- and post processing that also affect results.
The average prompt clocks in at some twenty words, for which we get a full image of 1024x1024 size or more. In information terms, that’s a lot of output retrieved and automatically assembled, from very little input supplied.
Compare that to the creation of original works, where every last element of the image is arranged by hand.
Infinite algorithmic remixes is a fascinating achievement.
It’s a shame it is still being presented as if the model doesn’t exist, nor store anything.
Here’s hoping this grounding in actual visual creation process, and in a real computer context, helps it click.