


Sam Altman and the Sorcerer's Stone, part II
The man with the smiling mask, the two anti-wizards, and the girl who wouldn’t disappear


Originally published on LinkedIn on the same day as the two new class action lawsuits against OpenAI — one from the public over privacy, one from authors over copyrights.
Part I • Part III
The race to AI dumbinance

As the no doubt charming CEO of the adorably mascoted machine learning community (that warm fuzzy word again!) Hugging Face, today’s gentle guardians of that precious Books3 collection, told the US senate, while wearing his very best suit:
“Innovation and Open Source is Really Important to Stay Ahead and Not Fall Behind And Be Competitive And Also Democratic And Innovative And Ahead And Innovative And Stuff.”
Yes, those are the literal words he used.
No, not really. Come on.
But this threat of being less modern, less competitive, less smarterer, is also a recurring theme in AI CEO spiel. If you don't buy into conceding your integrity, hard-earned creative content and fundamental property rights for human flourishing – at least do it for king and country.
The go-to boogeyman here is China. Which is funny, as in this case, China is already hopelessly ahead of us.
In regulating the use of copyrighted content in generative AI, that is.
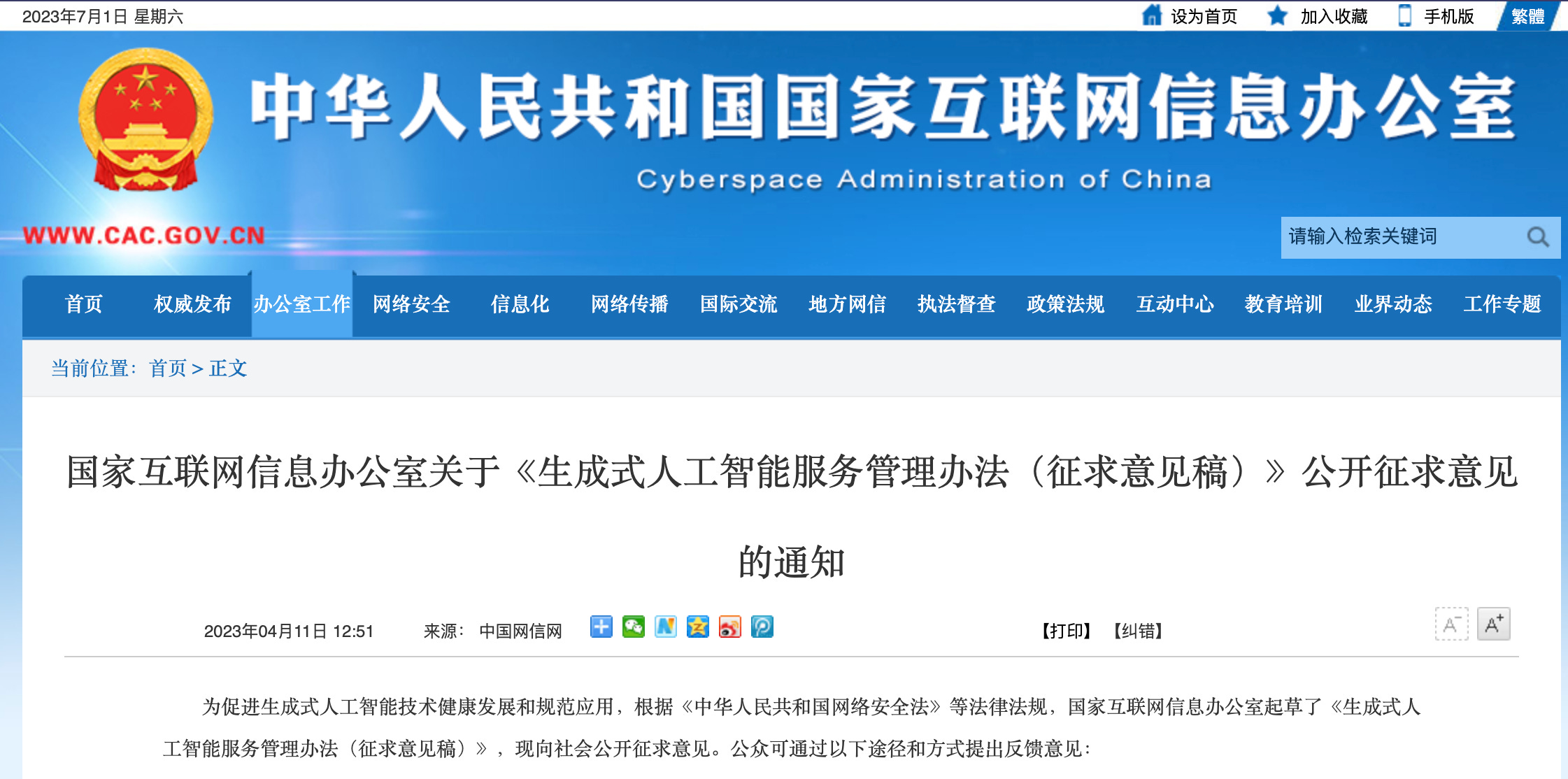
“4.3 Respect intellectual property rights and commercial ethics; advantages in algorithms, data, platforms, etc., may not be used to engage in unfair competition.”
– Actual for real quote from above April 2023 draft legislation. Clear and unambiguous legal text WHAT
To be fair, they also do that whole socialist dictatorship thing. So there is that.
But contrary to what one remarkably influential anonymous techno-fascist blog would have you believe, countries who did not already shield their creative industries from AI ingestion by law from lack of foresight, now rush to respond to industry concerns.
How does it DO that?
This is where we come to the heroes of our story.
No, not Sam Altman and David Holz. Although we will get to Mr Holz.
First off, a guy called Peter Schoppert. Most of this story is based on his research. His Substack bio reads:
“Publisher with more than 20 years experience, Director of NUS Press. With a strong interest in public affairs: ex-McKinsey, Past-President, Singapore Book Publishers Association. Former tech entrepreneur (with a NASDAQ IPO).”
But don't take it from me taking it from him, a direct actual first-hand source. Let's have ChatGPT do it:
“A visionary entrepreneur known for his groundbreaking work in renewable energy and social entrepreneurship. With a strong engineering background and a passion for sustainability, he co-founded a tech startup that revolutionized the energy sector and actively supports initiatives for social impact.”
Right.
While most of us were distracted by stupid bot tricks like the one above or busty anime girls with too many fingers or cheating on homework and whatnot and might not honestly care all that much about some snobby weirdo writers and artists getting drowned out by a gajillion Amazon bot-books and Etsy prompt-art-posters that turns author's own works against them ("do those spoilt artcels some good, get 'emselves proper jobs"), Peter and friends made a very thorough job of mapping out what published work went into The Pile.
And let me tell you, he is neither impressed nor amused.

The visible tracks outlined in his investigations lead to Meta, EleutherAI and others who openly use The Pile. Of course Altman and friends' entire business model depends on keeping sources secret – nearly no foundation models comply with coming transparency law – so the tracks stop at their doorstep.
But it's quite simple to try for yourself. If not from the Harry Potter series, then from some of the other 196,993 books.
Until very recently, ChatGPT had no qualms quoting entire passages from books when prompted. However, after University of Chicago Professor Ben Zhao – the second and final hero of this story – brought this to the attention of a Microsoft employee on twitter, that all changed over the following weekend.

In a twit of irony, Elon put a temporary login-wall against, get this — unethical scraping — which means twitter servers are busy DDOS:ing themselves. You might have to check back later on that link above.
So anyway, they fixed the problem. Sort of:

You will now have to wade through some carefully human-wrought wording on access to copyrighted works, so buttery-smooth you will have to re-read it three times over, at the slightest mention of a certain rights holder. But from there on, all it takes is the tiniest coaxing to remove any doubt that gen-AI does indeed "memorize data".
Or in muggle words: "store intellectual property." (We’ll do more of that sort of translation in the concluding part.)
And even if those "memorized" passages now come with a disclaimer, the content is still there, contributing a crucial part of the product's value. Not just when directly asked or even when directly visible, but to broadly boost the range and quality of writing – all in support of that precious illusion of sentience.
And all without permission, credit or compensation to any of the authors and rights holders.
Fitting responsibility

The story of OpenAI and Harry Potter mirrors that of Midjourney and the Afghan Girl. Photographed by Steve McCurry for a 1984 NatGeo cover, Sharbat Gula’s portrait is one of the world’s top 100 most famous pictures. When Midjourney 3.0 repeatedly spat out near-identical copies of the original, Holz and his merry band quickly found a “solution”. You simply got a warning instead of a picture, and repeated “abuse” got you an NSFW ban.

Power users quickly found workarounds though.
Apparently Midjourney feel more comfortable with their 5.2 release, so now both “Afghan Girl” and “Sharbat Gula” is back on the menu, boys! Just not in combination with "Steve McCurry”, “National Geographic” or any other specific qualifier. “Steve McCurry” is still verboten altogether.
As you can see, it works out spectacularly:

Fans and CEO alike keep pretending that the big issue is original-to-output infringement — which to be sure is a real product defect exposing customers to real legal risk, albeit small. But Holz is abundantly clear — at least in the fine print — that when that zeppelin inevitably sails, he’ll happily throw paying customers and fans alike under the Hogwarts Express. Just as he did by selling his product to millions of users under the pretense that machine output is copyrightable.
This allows happy piracy-peddlers Adobe to look like the comparatively lesser evil by offering to foot the bill for such mishaps.
But let’s be real here:
Output quality correlates directly to input quality.
That difference has a marketplace value.
And the better machine output gets, the more it competes directly against the originals, and the less those are worth on the market.
Licensing copyrighted material should have already happened.
And weaponizing creative works against their makers should come at an even steeper price. But it doesn’t. Yet.
For any such licensing negotiation to be even remotely fair, the well established. universal, fundamental, right to consent – which neither Midjourney nor Adobe “offer” their contributors – is paramount. And without auditable data transparency, degenerative AI companies hold all the cards.
Data transparency law may need years to grow teeth, during which pirates prosper and creatives and rights holders bleed. But more urgent action is under way.
© Johan C. Brandstedt. All rights reserved.
Which is incidentally the legal default for original content on the internet, unless otherwise noted. How about that?
This text available for re-publication with advance written permission by the author.