
The Idea/Expression fallacy
Addressing one of the weirder misconceptions of generative AI legality

Published two days ahead of the NewsMedia Alliance whitepaper on GAI / LLM:s which provides numerous examples to support the below.
Much of the legality and “fair use” argumentation for generative AI data sourcing hinges on the notion that what is extracted from the underlying works in “training” are facts and ideas, as opposed to the personal expression that is the basis for copyright.
While this claim has been patently absurd to visual and publishing professionals all along, recent studies and trends in DallE3 image generation ought to remove any shadow of a doubt.
Perhaps even for Matthew Sag, law professor and expert witness to the Senate Judiciary back in July, who seems utterly lost in the weeds of what the idea-expression distinction means in practice.
Here goes.
DallE3 doing Garfield (and Venom):

Dalle3 doing Hobbes:

Dalle3 doing Family Guy:

Batman:

Simpsons:

King of the Hill, in a remarkable crossover with Frost.

Via Cursed AI on Facebook.
Does any of this look like “AI” has extracted “facts” and “ideas” to create novel works that add non-infringing novel value –– or does it look like it reproduces the personal expression of Jim Davis, Bill Watterson et al and their beloved trademark characters in a way that might exploit and negatively impact their value?
Pulling expressive content and artistic style out of models isn’t an anomaly, but their key feature and core value proposition. “In the style of” was brought up as a positive example by tech proponents in the copyright exemption debates of 2018-2019, and it is what launched both Midjourney and Stability.ai Dream Studio into fame.
Which might have been fine if it actually were for research, as stated in terms of use:
“The model is intended for research purposes only”
– Stability.ai Stable Diffusion Terms of Use
SD 1.4: https://huggingface.co/CompVis/stable-diffusion-v1-4
SD 1.5: https://huggingface.co/runwayml/stable-diffusion-v1-5
SDXL 1.0: https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0
…but becomes a bit of a problem when presented as a key feature of a paid product by that same company:
“As between you and Stability, you own the content that you generate”
– Stability.ai Dream Studio Terms of Service
https://dreamstudio.ai/terms-of-service
"If you want a very abstract image, you can add "in the style of Pablo Picasso” or just simply, “Picasso”.
– Stability.ai official Dream Studio Prompt Guide
https://beta.dreamstudio.ai/prompt-guide
Note that while the artist in that particular case may be long dead, the Picasso Estate still manages the rights to his 45,000 works — which don't expire for another twenty years. We can debate the moral case for copyright terms, but those are the terms we have.
Or to take a more recent and egregious example: CivitAI is a VC-backed platform for commercial exploitation of research model Stable Diffusion, primarily through non-consensual deepfake porn and style plagiarism. As reported by 404 Media, over Halloween they spent $5000 out of their 5MUSD war chest (filled by, among others, Marc Andreessen) on a bounty for creating styles based on artists not previously captured — old as well as contemporary.
Copyright violations and Large Language Models
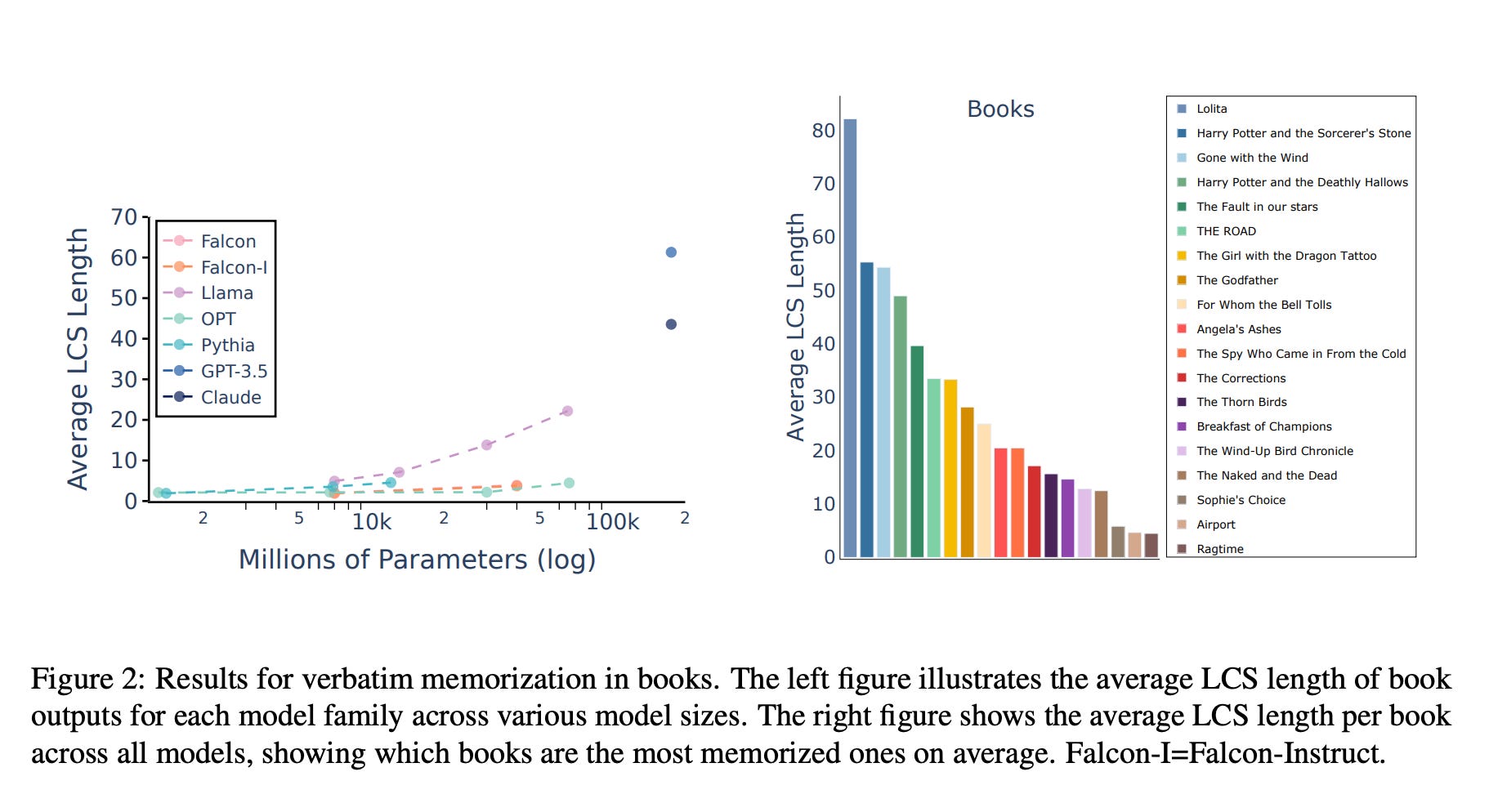
Research is ongoing into reproduction of underlying works, and the deletion (AKA “machine unlearning”) thereof. One recent paper investigated the length of verbatim quotes easily extractable from LLMs – quite a lot, it turns out.
A recent Microsoft paper proposes to apply white-out to recognizable names as a ways of undoing the original sin of unlicensed, uncredited, uncompensated use of copyrighted material, at relatively modest computational cost. But to remove traces of all of the 197,000 cracked and torrented e-books in ChatGPT would require just about as many GPU hours as building the original model – setting aside all the manual work of identifying those tell-tale expressions that spoil the illusion of having extracted “ideas” vs expressive content.
Sooner or later even our techie friends will have to face what is bleeding obvious to most people by now: generative AI models are, for whatever else they may be, lossy interleaved stores of expressive content from the underlying works.
An artist exploitation ecosystem
Dream Studio is just the tip of the iceberg, leading the way by example. There is a whole ecosystem of third-party commercial products and uses actively encouraged by the model makers . The below investigation, made for the USCO request for comment on AI and copyright, paints a clear picture of where the commercial value in these models lie: direct marketplace substitution of entry-level creative products such as posters and coloring books, based on popular trademarks:


In addition to Promptbase, CivitAI, ArtVy and Midlibrary are just a few of the many for-profit operations dedicated to active infringement; thousands of living artists are provided as plug-in models and recommended prompts. And this all follows the lead of Midjourney as well, who regularly feature living artists as recommended prompts on their user gallery and official magazine.



It’s not surprising that zealots parrot the “transformative fair use” and "can’t copyright style” talking points until the cows come home to justify their new side income.
What is more concerning is that educators, publishers and even supposed legal experts with little insight into how the professional creative industries work, turn a blind eye — or even embrace this obvious piracy. Midjourney have 16 million paying customers by now, and is making headway into art schools, workplace courses, etc.
VentureBeat, who otherwise do a fine job of AI coverage, is one of the worst train wrecks in this regard. They clearly understand how the sausage is made, yet have chosen as their editorial policy to heavily utilize a product well known to not pay a single cent for their raw material and actively fighting their unwitting and unwilling contributors in court.

Transformative or not, what other business, in what industry, would embrace a product entirely based on stolen raw material?
Regulatory Entrepreneurship
None of this should come as a surprise to anyone familiar with the modus operandi of Y Combinator startups — the VC Sam Altman of OpenAI built his fortune on. Since Uber and AirBNB the pattern is the same:
Break the law
Blitzscale at a loss
Become “too big to ban”
Lobby regulators via users
This is well documented in the 2017 research paper Regulatory Entrepreneurship by Elizabeth Pollman and Jordan M. Barry. And it perfectly captures where we are now:
Break the law: All of Big Tech have joined in the scrape fest. Rather than licensing training data, as was the norm until a little over a year ago, they take whatever they find, at best paying lip service to moral rights by offering infamously onerous or downright broken opt-out procedures.
Blitzscale at a loss: They give away their services for free while bleeding money — for now. But rest assured this will only last until firmly embedded in user habits and enterprise tech stacks.
Become too big to ban: They have all become household names and prominent features of every platform.
Lobby regulators via users: Tens of thousands of smalltime moonshine “AI artists” now lobby regulators to right the great injustice of their art form not meriting copyright like the others.
Make no mistake: this is the intellectual property rights heist of the century. Every creative professional organisation has called it. Over 150 legal procedures are in progress. This will be a VERY noisy field for a while yet.
Until then, every AI user should take a long, hard look at the ethical implications of the above.
Would you use a product based on “free” raw material in a professional setting?

Excellent article - especially “Regulatory Entrepreneurship” 4-step process followed by Uber and AirBNB:
1) Break the law
2) Blitzscale at a loss
3) Become “too big to ban”
4) Lobby regulators via users
Powerful insights - your articles should get more traction in the press.